

My Best Recent Guides for AI Engineers
A curated list of the most actionable guides I’ve published in the past months.

Welcome to Neural Bits. Each week, I write about practical, production-ready AI/ML Engineering. Join over 7000+ engineers and learn to build real-world AI Systems.
In this week’s edition, I want to share three standout articles from my recent work that cover a mix of AI topics, including optimising and serving AI models both at scale and on Edge Hardware, and a few best practices for building Python Backends for your RAG or Agentic pipelines.
For each: a summary, why it’s valuable, and what you’ll learn by reading it.
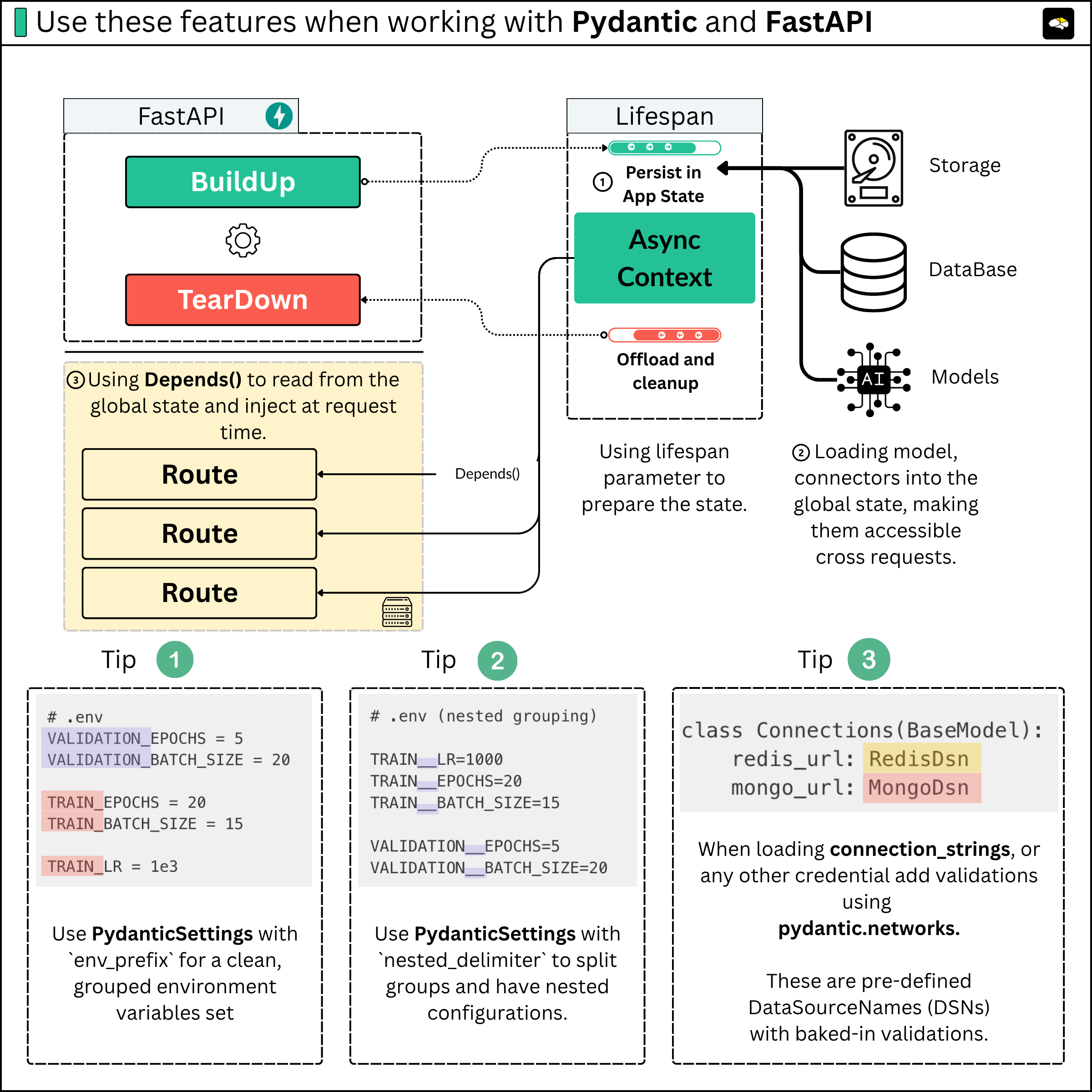
1. Use These 6 Advanced Concepts with FastAPI
This article introduces six advanced concepts you could use when building backends and APIs with FastAPI. It’s especially oriented at developers working with FastAPI and Pydantic, to help structure and manage AI or ML applications more robustly.
Topics include model lifecycle (loading/unloading), state management, dependency injection, configuration management, and best practices for production-ready code.
Why it’s a good resource:
It brings engineering discipline to AI projects, showing you how to use the FastAPI app lifecycle hook, properly work with Pydantic configurations, and write robust, scalable Python code.
It covers some pitfalls around code structure, configuration, and how to efficiently use the DTO (Data Transfer Object) design pattern with Pydantic to exchange data between your service layers.
What you’ll learn:
How and when to use dependency-injection in FastAPI for your ML/AI applications.
Best practices for model loading/unloading, managing state, and building maintainable code.
How to manage FastAPI’s application state.
How to properly use PydanticSettings for your secrets and environment variables.

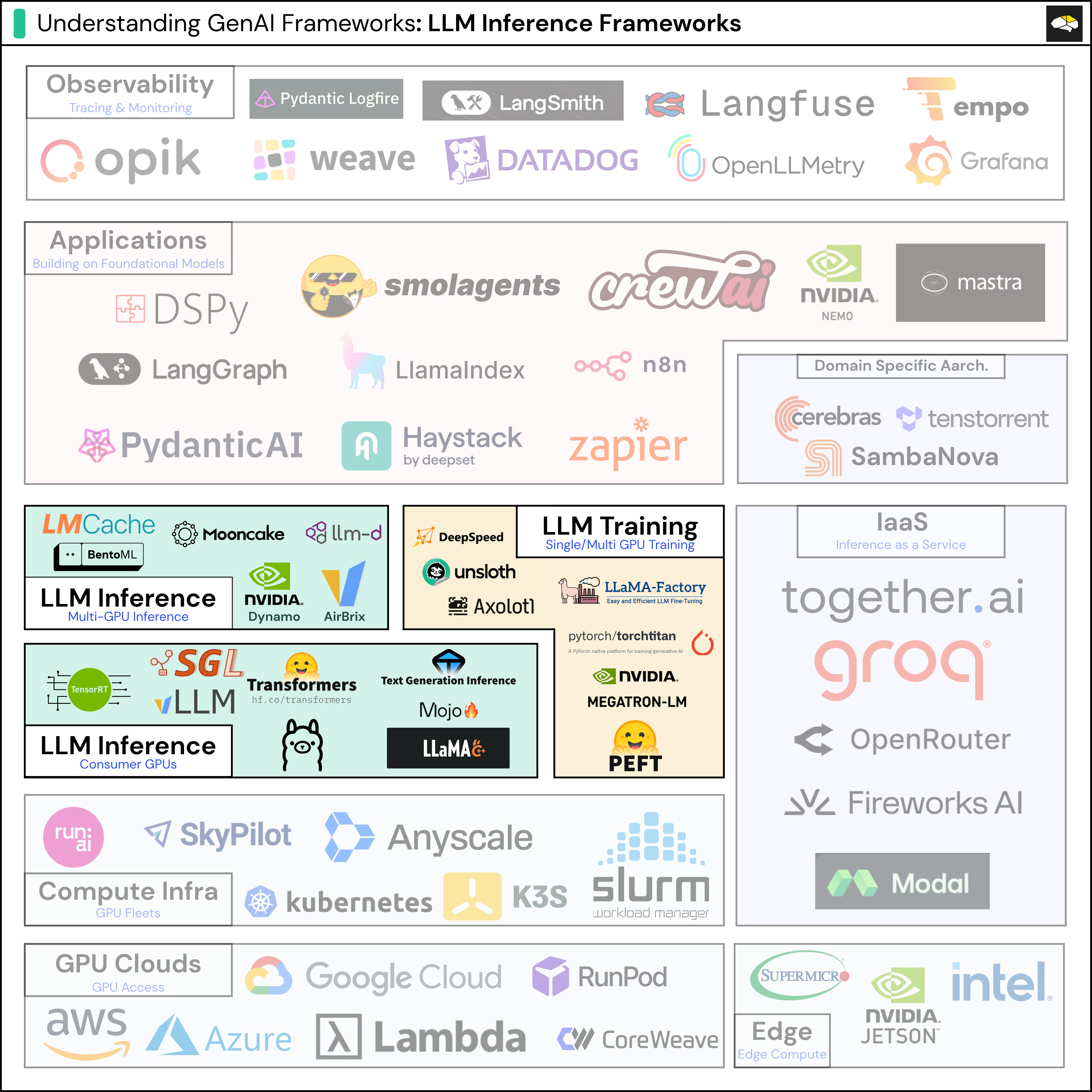
2. An AI Engineer’s Guide to Inference Engines and Frameworks
This guide describes the most popular Inference Engines and Frameworks an AI Engineer would use to port trained models into deployed, usable systems. Be it classical Deep Learning Models, LLMs, Finetuned LLMs or VLMs, this guide explains inference engines, serving frameworks, and what it takes to reliably serve AI models in production (latency, throughput, scalability, infrastructure).
Why it’s a good resource:
Provides a comprehensive overview of all the libraries and frameworks for AI Inference, used within Industry.
It’s practical and engineering-oriented: useful for anyone building real-world AI applications that aim to deploy at any scale.
What you’ll learn:
The model-to-production lifecycle.
How to select the Inference Engine and Framework for your model size, scale, system architecture and latency constraints.
The scope and inner workings of each engine and framework.

3. An AI Engineer’s Guide to Running LLMs on CPUs, GPUs and Edge (llama.cpp / GGML / GGUF)
This video guide explains how llama.cpp, GGML and GGUF work and how you can run LLMs locally - on laptop CPUs, mobile/edge devices, or consumer hardware. A large set of LLMs has big parameter counts and requires powerful GPUs with 20GB+ of VRAM to serve them. On the other hand, llama.cpp can serve quantised GGUF models that maintain close performance and accuracy, while drastically reducing the memory requirement by up to 4-5x times.
Why it’s a good resource:
It describes how model quantisations work and how GGUF compresses model weights.
It’s a practical guide for AI Engineers aiming to build local, offline, or edge-based AI applications, including AI Agents or Agentic Systems.
What you’ll learn:
What is llama.cpp / GGML / GGUF, how they work end-to-end, and why they enable inference on a wide variety of hardware (CPU, low-end GPU, edge devices).
How AI Engineers can inspect the layers of a GGUF model, and where to find GGUF models.

Ending Notes
Thanks for following along as I’ve been diving into the engineering side of AI these past couple of months. My goal with all these articles and guides has been to share and educate more developers to build real, practical AI systems past just demos.
This newsletter has been growing steadily and organically thanks to your support - and I’m incredibly grateful for that. 🙌
I’ve also been able to carve out more time recently, and I’ve started working on several big initiatives that I think will push this newsletter (and the whole project) into a new phase.
I can’t wait to share what I’ve been building, and what’s coming next!