

Piece of advice for AI Engineers
Answering a subscriber’s question: "Which NVIDIA AI Stack tools should an AI engineer know?”

Welcome to Neural Bits. Each week, my subscribers receive an edition on practical, production-ready AI/ML Engineering, building skills that you need in your AI/ML Journey. Join over 6200 engineers, and learn how to build real-world AI Systems.
A few days ago, a subscriber preparing for an interview at NVIDIA asked me a simple but important question:
→ “What do I need to know about NVIDIA software to stand out?”
That question made me realize something: while I’ve written about many of NVIDIA’s frameworks and libraries, I’ve never put together a clear step-by-step breakdown of what matters, where each tool fits, and why it’s important.
While most engineers focus on learning about the application layer, building RAG, Agents, or learning more about PyTorch, very few dive into the NVIDIA ecosystem that, in many ways, powers those frameworks.
This article is my attempt to bridge that gap for you. To keep it structured, I’ve broken it into these parts:
AI Engineer vs AI User
A Pragmatic Mindset against Hype
Future-proof on NVIDIA’s AI tooling
What an AI Engineer should know about it
Let’s decode it!
Setting the Ground
1. AI Engineer vs AI User
First, we have to make this important distinction:
An AI Engineer isn’t the same as being an AI user. An engineer doesn’t just call models through an API, rely on blackbox dashboards to track tokens and usages, or outsource data cleaning and fine-tuning to external tools.
The title engineer implies ownership: you understand how each part of the AI system works, and you can actively design, optimize, and integrate those components yourself.
Making API calls is one thing - building robust AI systems is engineering.
2. The Pragmatic Mindset
AI is exciting, but the hype can mislead. Many roadmaps, courses, and shiny projects exist, but it’s crucial to separate what’s flashy from what’s useful.
Why? Let’s take AI Agents as an example.
AI Agents are just a small part of what an AI System is and does, as an engineer you should focus on the entire system, not just the shiny part.
It’s easy to spin up a POC AI Agent today, but the real work begins when you face infrastructure, optimization, evaluation, data pipelines, security and production deployment.
It’s better to keep a pragmatic mindset, master the software engineering concepts, and think in end-to-end systems.
Speaking of a pragmatic mindset, here’s a snippet from The Pragmatic Engineer Newsletter article with Chip Huyen as a guest, only a single mention of Agents, multiple mentions of Infrastructure, Optimizations, Applications, and Security.
3. Why NVIDIA Matters
NVIDIA GPUs remain the standard for AI compute. Their ecosystem spans model training, inference, deployment, and optimization. Studying NVIDIA’s stack helps engineers understand the backbone of modern AI infrastructure.
Why the standard? Here are three recent NVIDIA Investments:
NScale raises $1.1billion backed by NVIDIA for the EU AI Supercluster.
xAI Collosus Cluster (200k NVIDIA Hopper GPUs)
Meta’s Gen AI Infrastructure (350k Hopper GPUs)
For you, this is a smart move to study and understand NVIDIA’s AI Ecosystem, as it powers a large chunk of AI Infrastructure.
Let’s decode it.
What an AI Engineer must know about GPUs
On this topic, you should know and understand the basic hardware principles of what a GPU is, how it works, and all the key terms that describe its capabilities.
Learning the Hardware Components
Cores
CUDA cores are good for general parallel computation, think of Shaders and Graphics rendering. Tensor cores are specialized for matrix multiplication, which is key in Transformer architectures.Memory Hierarchy
VRAM - the global GPU memory. This memory is the place where your CPU will copy Tensors, Activations, and overall Data that will be used by your GPU.
Shared Memory - This is smaller in size but much faster memory. This is the place where GPU kernel data resides. Your GPU will move data from VRAM to shared memory and then use it for computation, making it available across multiple threads.
Registers - Smallest and fastest. GPU registers serve as the fastest, thread-private memory for temporary data storage, and they’re used by the SMs (Streaming Multiprocessors) to do computations.
Precision
FP32 - This is the 32-bit Floating Point type, standard training format.
FP16/BF16 - Faster, less memory, commonly used for inference.
FP8 - New precision format, compatible with newer GPU architectures.
To get practical, see my article on GPU Programming with code.

Learning to read a GPU Cheatsheet
The idea for sharing this came from Andrej Karpathy’s video on Large Language Models. He starts with a nice introduction on how LLMs work, and then, when going through model training, he shares the H100 GPU Cheatsheet to look into Precision formats. (at 40:03 mark)

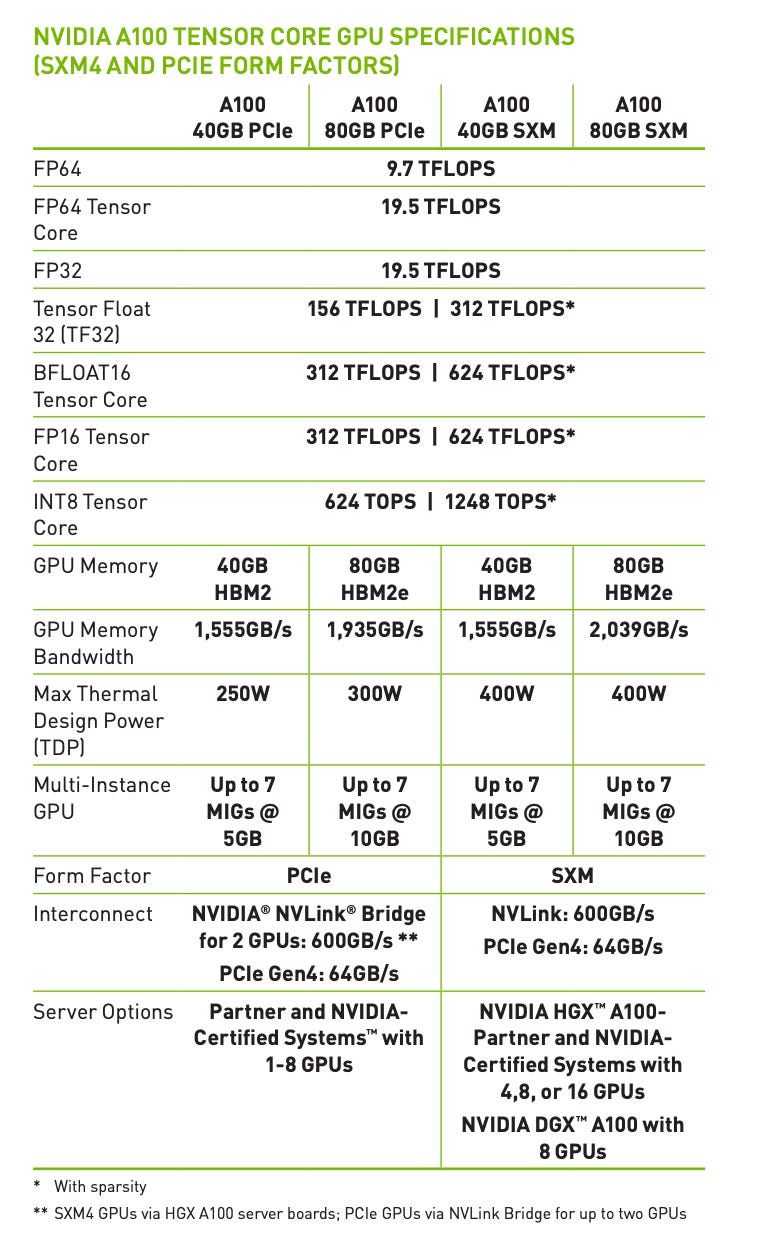
A cheatsheet contains the GPU performance details, covering the Bandwidth, Precision Formats, Architecture variants, and more. This will help you understand why some GPUs are better at specific precisions, compute saturation, arithmetic intensity, and overall workload.
As an AI Engineer, focus on learning at a high-level, how to extract key details about a GPU’s based on their cheatsheets. Find the A100 Cheatsheet below:
Optional Study on other GPU Variants
These are called DSAs (Domain Specific Architectures) and not GPUs.
During the Deep Learning boom (2012-2013), a GPU was known as a Graphics Card, to render complex graphics and shaders for video games.
Around the same time, ASICs emerged as DSAs, built specifically for crypto mining (BTC, ETH).
One of the reasons manufacturers build DSAs today is due to this:
A GPU has a memory hierarchy, which is general-purpose but not always optimal for AI workloads, especially large matrix multiplications in Transformers.
A GPU is a programmable, flexible accelerator, but not as powerful or power-efficient as a DSA.
A DSA, on the other hand, is highly specialized hardware designed for a narrow workload, in our case, AI Training and Inference.
Popular examples of DSAs for AI are Google’s TPU (Tensor Processing Unit, 2016), Cerebras, SambaNova, and Tenstorrent. The Groq LPU (Language Processing Unit), also released in 2016, is another DSA for Inference, which is very efficient.

Takeaway from here is to know that even if NVIDIA powers the largest chunk of AI Infrastructure, DSAs also emerge targeting narrow niches within AI Compute.
Must-knows about NVIDIA’s AI Stack
When it comes to deep learning and AI, NVIDIA is a big player. Besides the hardware, every AI Engineer would directly or indirectly have to use a software component from NVIDIA’s library.
That’s mainly because NVIDIA has built an ecosystem that supports every stage of AI development, across many industries and applications.
From core utilities to train AI models, to RL simulators, robotics, to enterprise-scale AI deployments. In this section, we’ll go over three components: Model Training, Optimization, and Deployment.
Learning about Model Training Utilities
CUDA is a parallel computing platform and API that powers the execution of all GPU kernels on the GPU. The cuDNN library contains a large set of primitives prebuilt for every compute operator or set of operators within your Neural Network layers. These two go hand-in-hand and are at the foundation of each AI model training/inferencing workflow.
A system-wide performance analysis tool to visualize an application’s algorithm execution flow. This will help identify the largest opportunities to optimize.
NeMo-RL
The NeMo library is a scalable and efficient post-training library designed for models ranging from 1 GPU to thousands, and from tiny to over 100 billion parameters. It seamlessly integrates with HuggingFace, so no overhead on that front.
Learning about Model Inference Utilities
TensorRT & TensorRT-LLM
This is a powerful compiler for AI models that will take the model graph, scan it, and optimize it for optimal settings on specific NVIDIA GPU hardware. TensorRT-LLM is a specific adaptation of the compiler for Transformer-based models.ℹ️ I’ve covered TensorRT in depth in the second section of this article.
Triton Inference Server
One of the most mature solutions for deploying general-purpose AI models in production.
ℹ️ I’ve covered Triton Server in depth in this article.Dynamo Inference
Dynamo is the newest framework in NVIDIA’s Stack, specifically designed for large-scale Generative AI workloads.
ℹ️ I’ve unpacked the Dynamo architecture in this article.



Learning about Model Deployment Utilities
NVIDIA GPU Operator
By adding this operator on top of your K8S cluster, you’ll enable lifecycle management of GPU resources, handling driver installation, runtime libraries, and configuration for GPU-accelerated workloads.NVIDIA NIM
A NIM comes from NVIDIA Inference Microservice. It is a component that prepackages the optimal setup for a GenAI model, making it deployable at scale in a robust manner. Although customizable, NIMs are enterprise-first.
ℹ️ I’ve covered NIM in this article.KAI Scheduler
The KAI Scheduler was initially developed by Run:ai and is a Kubernetes-native GPU scheduling solution designed to optimize resource allocation for AI workloads. NVIDIA acquired Run:ai for $700 million, integrated it, and then open-sourced KAI Scheduler.

Conclusion
In this article, we started by comparing an AI Engineer to an AI User, outlining that an AI Engineer does more than just build applications.
They need to understand every component of an AI system.
From there, we gave examples showing why it’s important to grasp end-to-end systems thinking, past the POCs, and not focus on hype and trends. Understanding these areas helps engineers design systems that scale efficiently and perform reliably.
One important topic was why AI Engineer often works directly or indirectly with NVIDIA’s tools, since NVIDIA powers a huge portion of AI compute.
The article covered GPUs, the difference between GPUs and Domain-Specific Architectures (DSAs) as a starter, and then explored libraries and tools for training, inference, and deployment, part of NVIDIA’s AI stack.
This guide is a starting point for any AI Engineer who wants to understand the ecosystem of NVIDIA hardware and software, which is something one most certainly will encounter in their work.
Even though most AI Engineers focus on building data pipelines, training models, and creating applications on top of foundational models, the concepts discussed here are essential for understanding the engineering behind the systems, including infrastructure, optimization, and efficient deployment.
Thank you for reading, see you next week! 👋
References
NVIDIA-NeMo/RL: Scalable toolkit for efficient model reinforcement. (2025, August). GitHub. https://github.com/NVIDIA-NeMo/RL
NVIDIA/KAI-Scheduler: KAI Scheduler is an open source Kubernetes Native scheduler for AI workloads at large scale. (2025, September 17). GitHub. https://github.com/NVIDIA/KAI-Scheduler
NVIDIA Dynamo. (2025). NVIDIA Developer. https://developer.nvidia.com/dynamo
Orosz, G., & Huyen, C. (2025, May 20). The AI Engineering Stack. Pragmaticengineer.com; The Pragmatic Engineer. https://newsletter.pragmaticengineer.com/p/the-ai-engineering-stack
Browne, R. (2025, September 25). British AI firm Nscale raises $1.1 billion in Nvidia-backed funding round. CNBC. https://www.cnbc.com/2025/09/25/nvidia-backed-uk-ai-firm-nscale-raises-1point1-billion-funding-round.html
Lee, K. (2024, March 12). Building Meta’s GenAI Infrastructure. Engineering at Meta. https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/
Kerstin. (2023, September 21). FPGAs vs. GPGPUs. IBE Electronics. https://www.pcbaaa.com/gpu-vs-gpgpu-vs-dsa-vs-fpga-vs-asic/
Invited: The Magnificent Seven Challenges and Opportunities in Domain-Specific Accelerator Design for Autonomous Systems. (2024). Arxiv.org. https://arxiv.org/html/2407.17311v1
Images and Media
If not stated otherwise, all images were created by the author.
Great stuff, this is all very important. maybe also go over similar skills for non-NVIDIA tools, too? thanks!