

Small VLMs Will Soon Compete With Frontier AI Models 10x Their Size
What makes NVIDIA Nemotron Nano 2 VL a breakthrough in small, fast, long-context visual reasoning.

Welcome to Neural Bits. Each week, I write about practical, production-ready AI/ML Engineering. Join over 7000+ engineers and learn to build real-world AI Systems.
The current edition of this newsletter is the second part in a small series titled “The Future of Agentic AI is Small”, where we unpack the technical details of NVIDIA’s Nemotron Family, a set of models, datasets, and techniques that push the boundary of Agentic AI to smaller, open, and more efficient models.
In the first part, we’ve covered the model family on a high level, spanning Nano 1B-15B models for Edge, Super 16B-50B for mid-tier, and Ultra 50B+ parameter models, which compete with frontier-level models on various benchmarks.
In the second part, we’ll focus on the multimodal star of the NVIDIA Nemotron Nano models, the Nano 2 VL 12B, released just a few weeks ago.
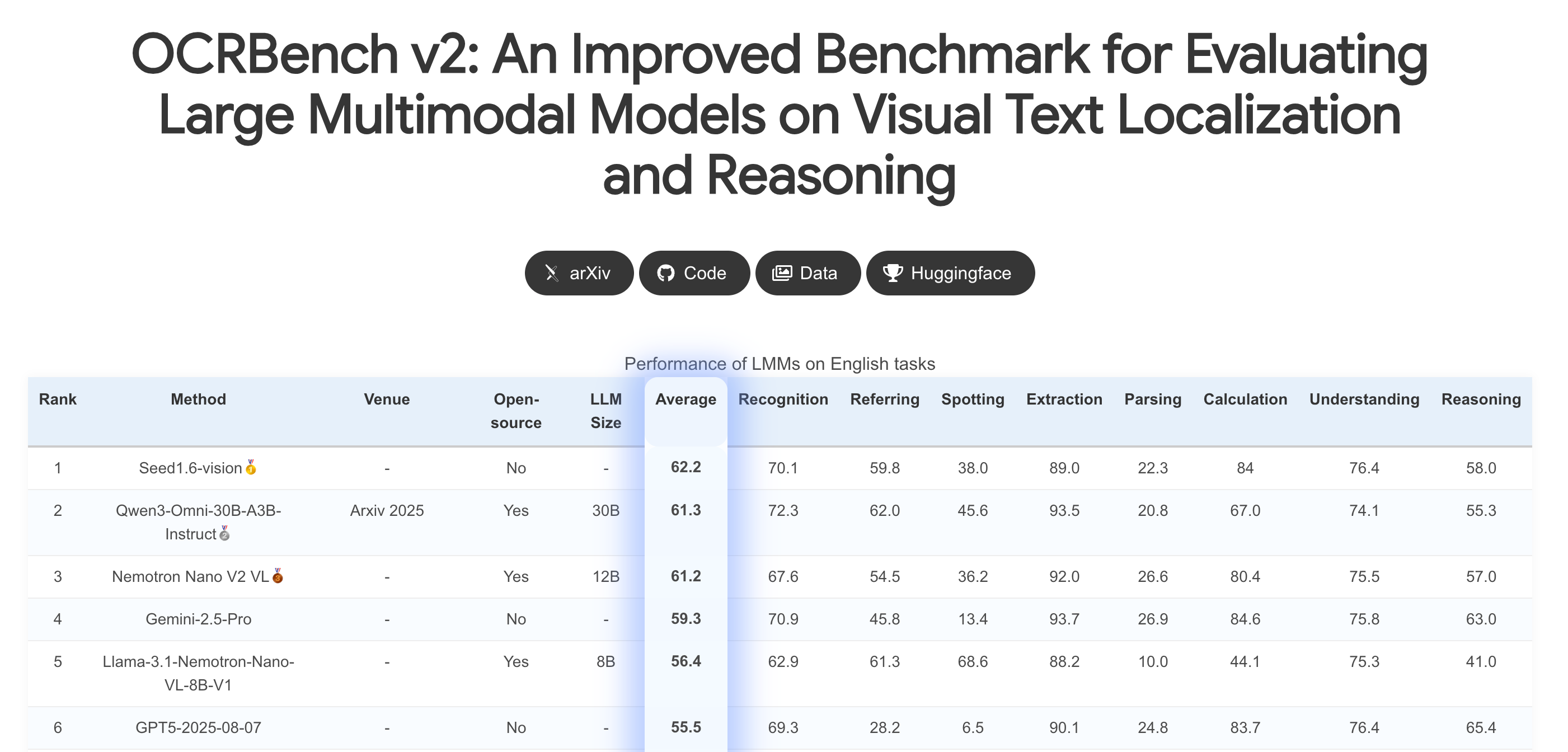
The Nano 2 VL 12B is the current leading open SVLM in the OCRBenchv2 benchmark, a benchmark designed to evaluate enterprise-scale document, invoices, and complex image understanding.
We’ll cover the architecture, the text encoder, and the vision encoder that the Nano 2 VL uses, and explain the architectural improvements, the plug-and-play optimizers, reasoning modes, and more.
In this mini-series:
→ ✅ Part I - The Nano 2 Family of SLMs for best-in-class Reasoning Models
→ ✅ Part II - The Nano 2 VL Model for Agentic AI capabilities on Vision Tasks
1. The Nemotron Nano 2 VL 12B
The Nano V2 VL was designed for strong real-world document understanding, long video comprehension, and multimodal reasoning. Compared to its predecessor, the Llama‑3.1‑Nemotron‑Nano‑VL‑8B, this version packs improvements across multiple vision benchmarks, notably on complex OCR-related benchmarks and Video/Image reasoning ones.
It does that through enhancements in architecture, image processing tweaks, dataset curation, training recipes, and inference optimizations, all of which are described in the research paper, and which we’ll cover in this article.
To outline a summary of the improvements Nano 2 VL brings:
Leading accuracy on document/OCR/vision-language tasks, placing Top 1 in SLM Open Models and Top 3 competing with frontier models such as Gemini 2.5 Pro.
Context handling from 16k tokens in the previous Nano VL (v1), up to 128k context window, enabling very long documents / long videos / multi-page inputs / complex reasoning.
Architecturally, built on a hybrid “Mamba-Transformer” backbone, bringing faster inference due to the linear compute time that Mamba + State Space Models (SSM) brings, as well as a powerful Vision Encoder trained on multi-scale resolution images.
Throughput in video handling with “Efficient Video Sampling (EVS)”, a technique to reduce redundant tokens in long videos and multi-image setups.
To understand the impact of these improvements that Nano v2 VL brings, first, we need to briefly cover the previous iteration of this VLM and pinpoint the performance, accuracy, its architecture, and rankings.
1.1 The Nemotron Nano VL - 8B (previous version)
The previous Nemotron VLM was built on the powerful Meta Llama 3.1 architecture for the Language Decoder and the C-Radiov2-H Vision Encoder by NVIDIA. The language decoder in the first version, Llama-3.1-Instruct-8B, is Meta’s mid-sized instruction-tuned LLM for high-quality reasoning and task-following.
Being an Instruct model, during post-training, it was aligned to adhere to user prompts and preferences, making it perform reliably in conversational tasks.
Architecturally, Llama-3.1-Instruct-8B uses a decoder-only Transformer with grouped-query attention that helps inference throughput, but we’ll see in a bit how that differs from what the Text Decoder in Nano 2 VL brings.
For the Vision Encoder, the previous Nemotron VL model used NVIDIA RADIOv2 Vision Encoder. This encoder was built under a paradigm called “agglomerative modeling”. That means that instead of relying on a single specialized teacher model, the design distills multiple teacher vision models simultaneously into a single student backbone that learns to mimic all of them across all resolutions. We’ll see more details on this one in a bit.
Now, let’s present an overview of what we’ve discussed above, in the following Figure.

Although it’s an SVLM (Small Vision Language Model), with only 8B parameters, it still ranked high on multiple Multimodal Tasks, including AI2D, OCRBenchv2, and ChartQA. Just to get an idea of what the data from these benchmarks looks like, let’s inspect a few samples from the AI2D Benchmark, where the Nemotron Nano VL (v1) scored 85% accuracy.
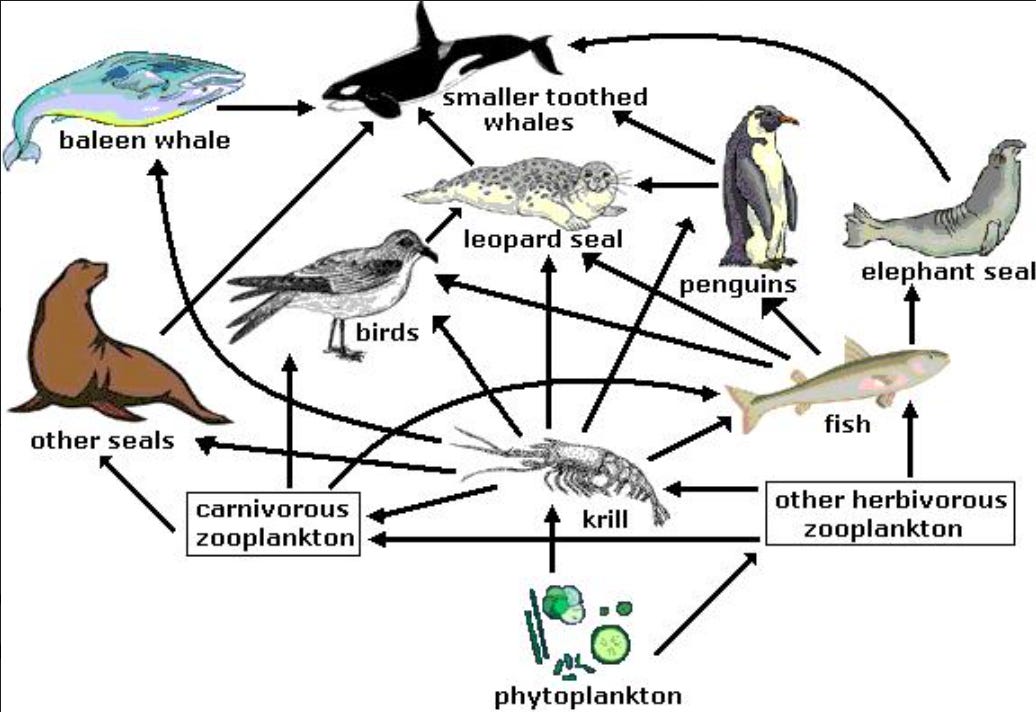
And to see a zoomed-in sample of an image in this set (3rd row), we can reason the complexity of the Task, the model having to reason across all the animals in the image, and also “understand” the connections between the arrows and the question & options presented:
Now that we have a complete overview of the previous Nemotron Nano VL version, let’s follow the same process for the Nemotron Nano 2 VL.
1.2 The Nemotron Nano 2 VL - 12B (the new version)
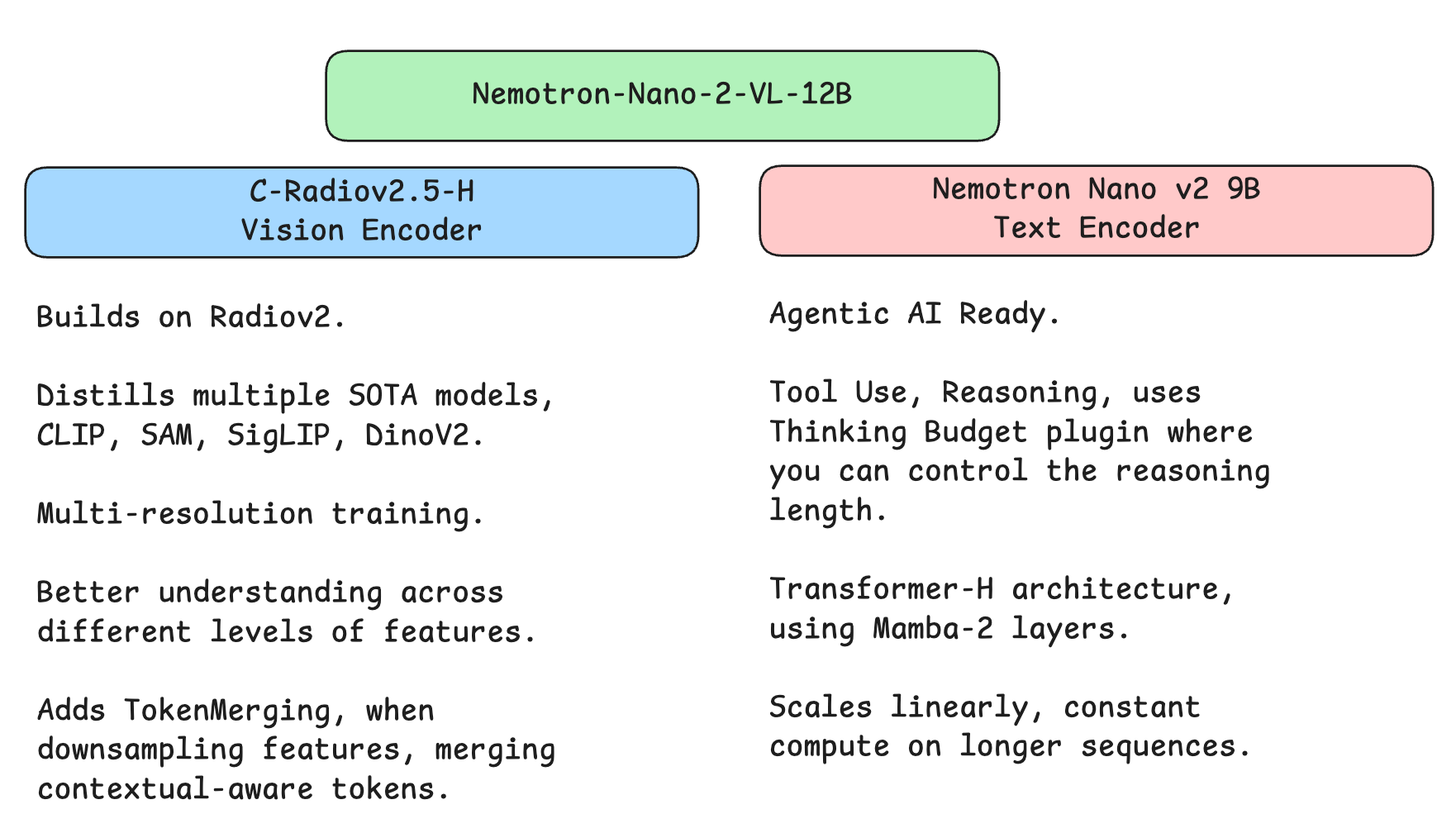
We could consider the Nano 2 VL model as built from the ground up, bringing changes to the Vision Encoder, Language Decoder, Post Training methods, and Image/Video processing workflow.
The Nano 2 VL builds on the Nemotron Nano 2 12B Language Model, this time, which is a more efficient and robust architecture compared to the Llama 3.1 used in the previous version. The Nano 2 - 12B LLM is a decoder-only stack where standard Transformer blocks are interleaved with Mamba-2 style state-space layers to improve efficiency and long-context scaling.
Note: We’ve covered the Nemotron Nano 2 12B Text Encoder model in the Part I of this article.
→ Read it here.
The Vision Encoder uses the same paradigm of “agglomerative models” but with a newer variant, c-RADIOv2-VLM-H, replacing the previous base and benefiting from improved multi-teacher distillation, multi-resolution consistency, and stronger dense features and robustness.
To put everything in a single Figure, we’ll have:
This time, the Nano 2 VL model is the leading open SVLM on the OCRBenchV2. To inspect a few samples of this benchmark, we have very complex use cases across invoices, documents, charts, and banners with tasks on Text Recognition, Ad Placement, Math Calculation, VQA (Visual Question Answering), and Text Extraction.

Now, let’s compare them side-by-side using a bar-chart across a variety of Multimodal Benchmarks, designed for Document Understanding and Image/Video reasoning tasks:
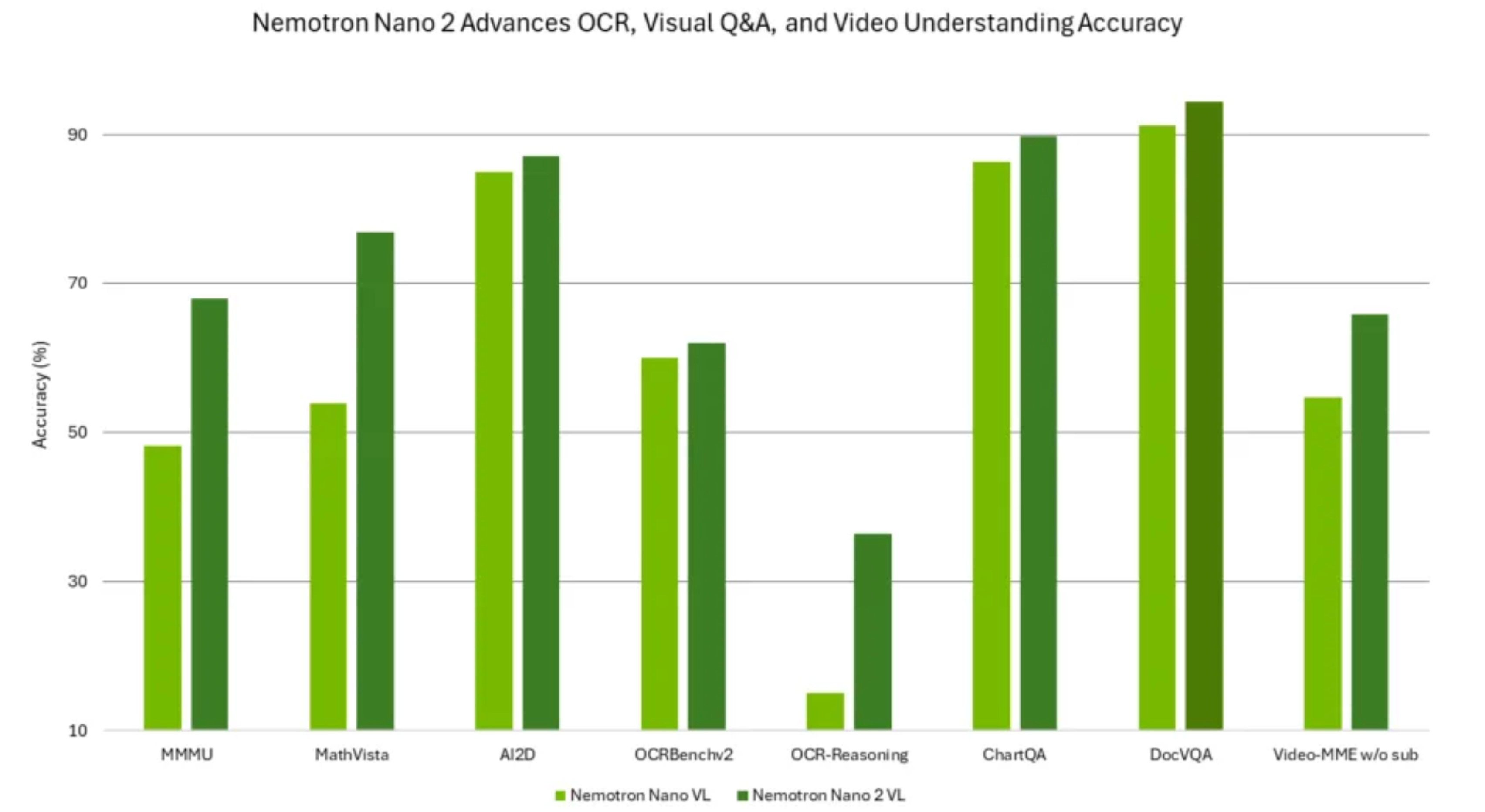
Now that we have a clear idea of how these models are different and what improvements the Nano 2 VL brings, let’s inspect in more detail the interesting parts of the Vision Backbone (the RADIO Encoder) and the techniques used to align this model in post-training, as well as why EVS is important and how it works.
2. Understanding the RADIO Vision Encoder
RADIOv2.5 is an “agglomerative” vision encoder by NVIDIA, which is trained by distilling multiple top VFMs (Vision Foundation Models) such as OpenAI CLIP, Meta DINO, and Meta SAM into a single backbone.
Instead of inheriting the bias of one teacher, it learns the strengths of many teachers, keeping global semantics, dense features, and segmentation-friendly spatial maps. An overview of that process could be seen in the following Figure.
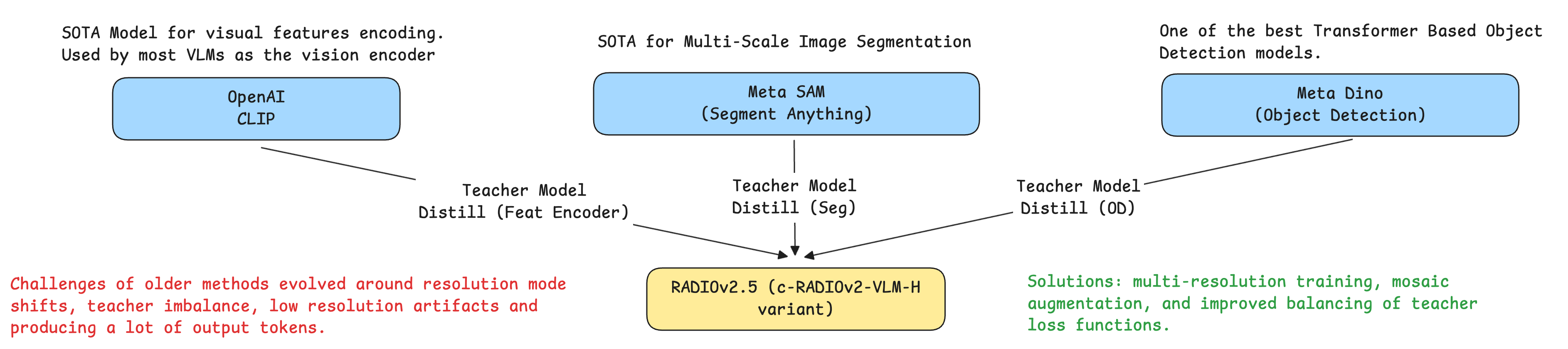
Document understanding or encoding images with complex details is a difficult task for Vision Models. Small text, skewed images, or low-resolution images pose a challenge for pretty much any VLM. The RADIO encoder mitigates that with multi-resolution consistency. Earlier encoders produced different features at different resolutions. RADIOv2.5, on the other hand, is trained with paired low/high-res teacher signals, so its features stay consistent across scales.
Let’s understand how exactly that works, using the following Figure 8:
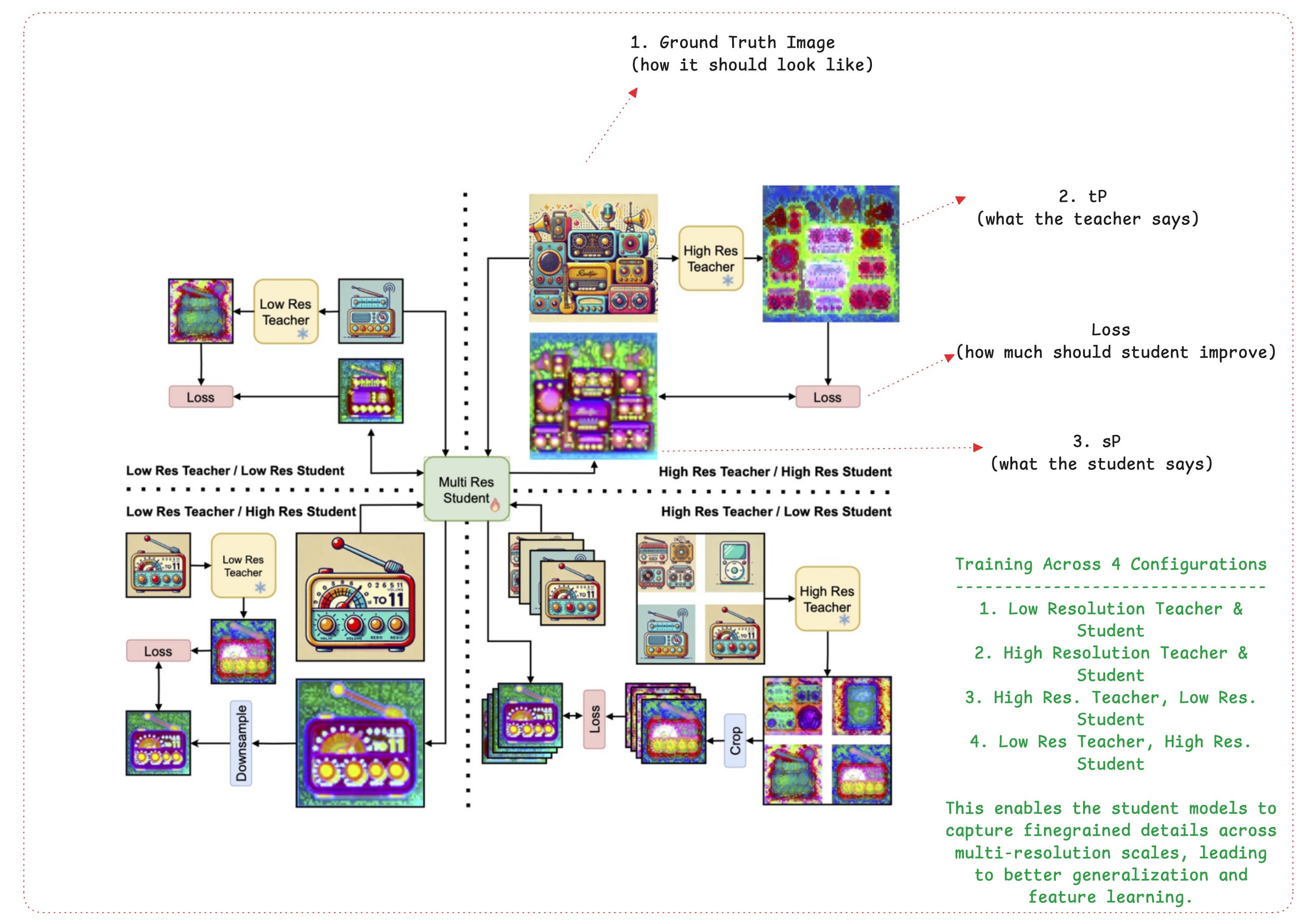
Here, we have 4 configurations (iterations) of a model training step. Each mode uses a different Teacher configuration, enabling the student to learn both features at high resolution and at low resolution at the same time, thus generalizing better and maintaining accuracy.
Another feature of RADIOv2.5 is token merging. This compresses redundant regions while preserving important details, and helps keep the token counts low, which translates into the encoder being capable of processing more Images at once, or having longer videos passed as input.
Note: This is particularly important for high-resolution images passed as input, as they’re split into multiple tiles before being passed to the model. Merging tokens, helps keeping the information density high with fewer tokens, something that might cause challenges for other Vision Encoders, as preserving each token will quickly fill-up the context window.
Now that we’ve covered the internals of how the RADIOv2.5 encoder works, we could use Figure 9 from the RADIOv2.5 research paper to sum up an overview:
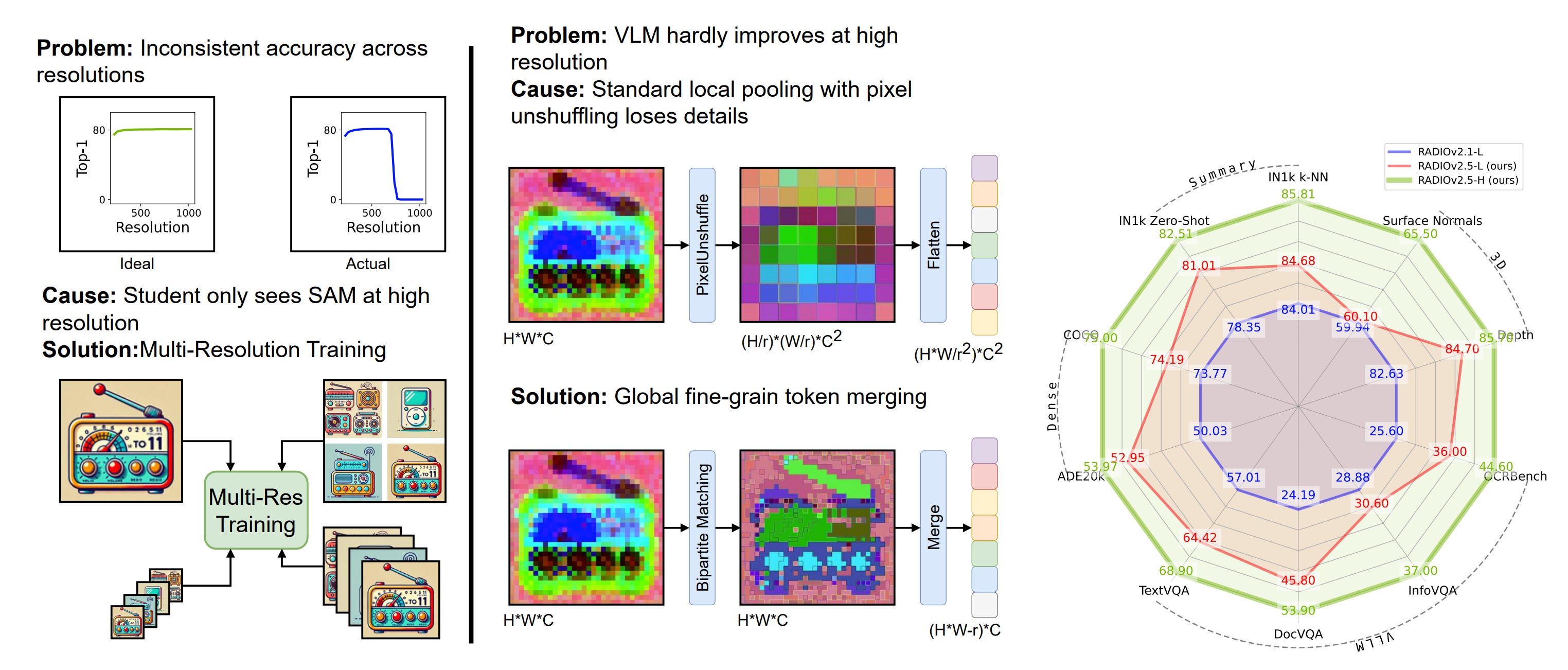
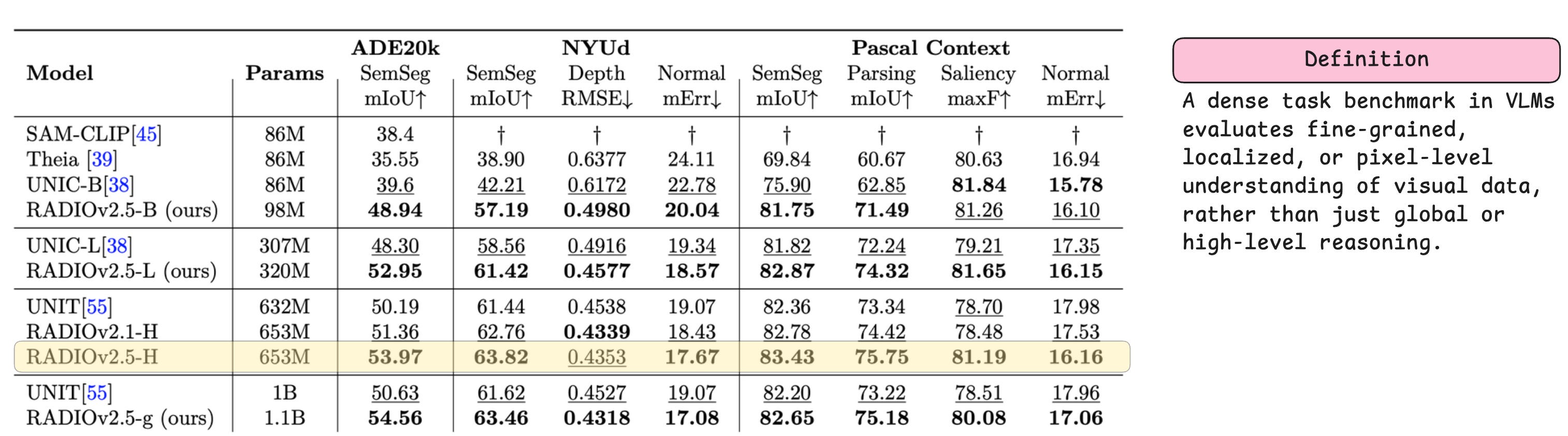
And as a last step of this section, let’s see a few benchmark results across multiple image-feature extraction tasks:
In the last section, we’ll bring everything together and use the official diagram for the Nemotron Nano 2 VL architecture, from the research paper, to outline each component and how it works - building on top of what we’ve learned in the previous sections.
3. Painting the Complete Architecture
From the Nemotron Nano 2 VL Research Paper, we get this Figure to visualize the architecture of the 12B model. Starting from the bottom up, we have the Text Input (prompt) and Image Input (represented as Tiled Image on the diagram).
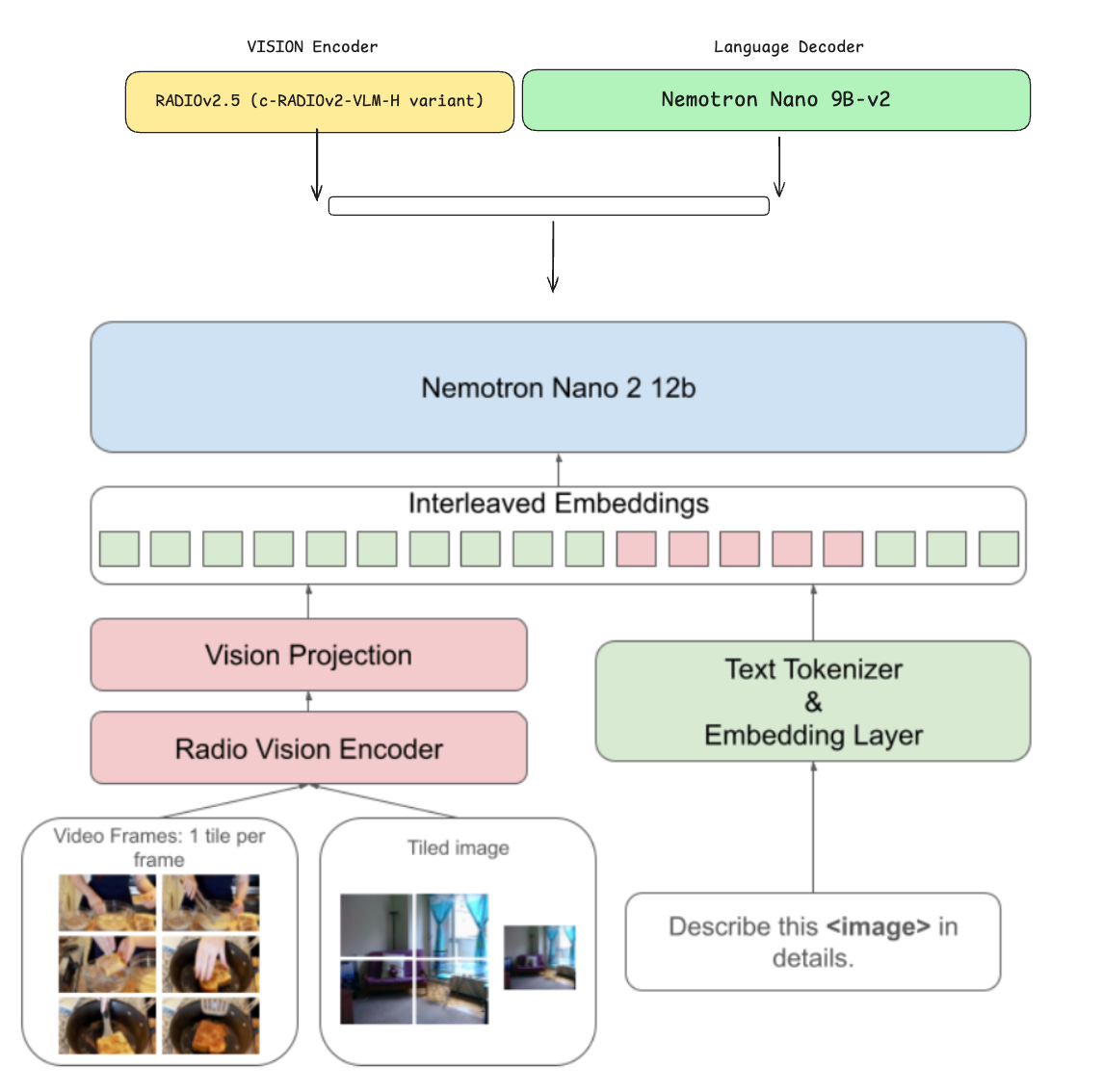
Both these inputs are passed through their respective encoders (i.e, Text is tokenized, Image is tiled and encoded, and tokens are projected), and all token embeddings land in a common, multimodal embedding space. Then, the Language Decoder processes interleaved (i.e, common space) embeddings and produces the answers.
Having this overall picture, let’s unpack the interesting components and provide a bit more detail on how exactly all these processes work. Since we’re covering the Nano 2 VL model, we’ll focus mostly on how Images/Videos are processed and passed through the model.
3.1 Starting with Image Tilling & Patching
Let’s first build the intuition on why we need to split images into patches and/or split them into multiple tiles.
Transformers were originally built for language, where input is already a sequence of discrete units (tokens). These tokens fit naturally into the Transformer architecture, because they have an ‘order’ and `position` in a sentence.
Images, however, are 2D grids, not sequences. A Transformer can’t directly take a 2D array of pixels and compute attention - it needs a sequence of vectors. So that’s why we convert an image into a sequence by slicing it into patches, to “mimic” the order of words in a sentence.
Note: In the end, embeddings for both words (text tokens) and visual patches (vision tokens) will end-up in the same latent embedding space for the Language Model to sample and process from.
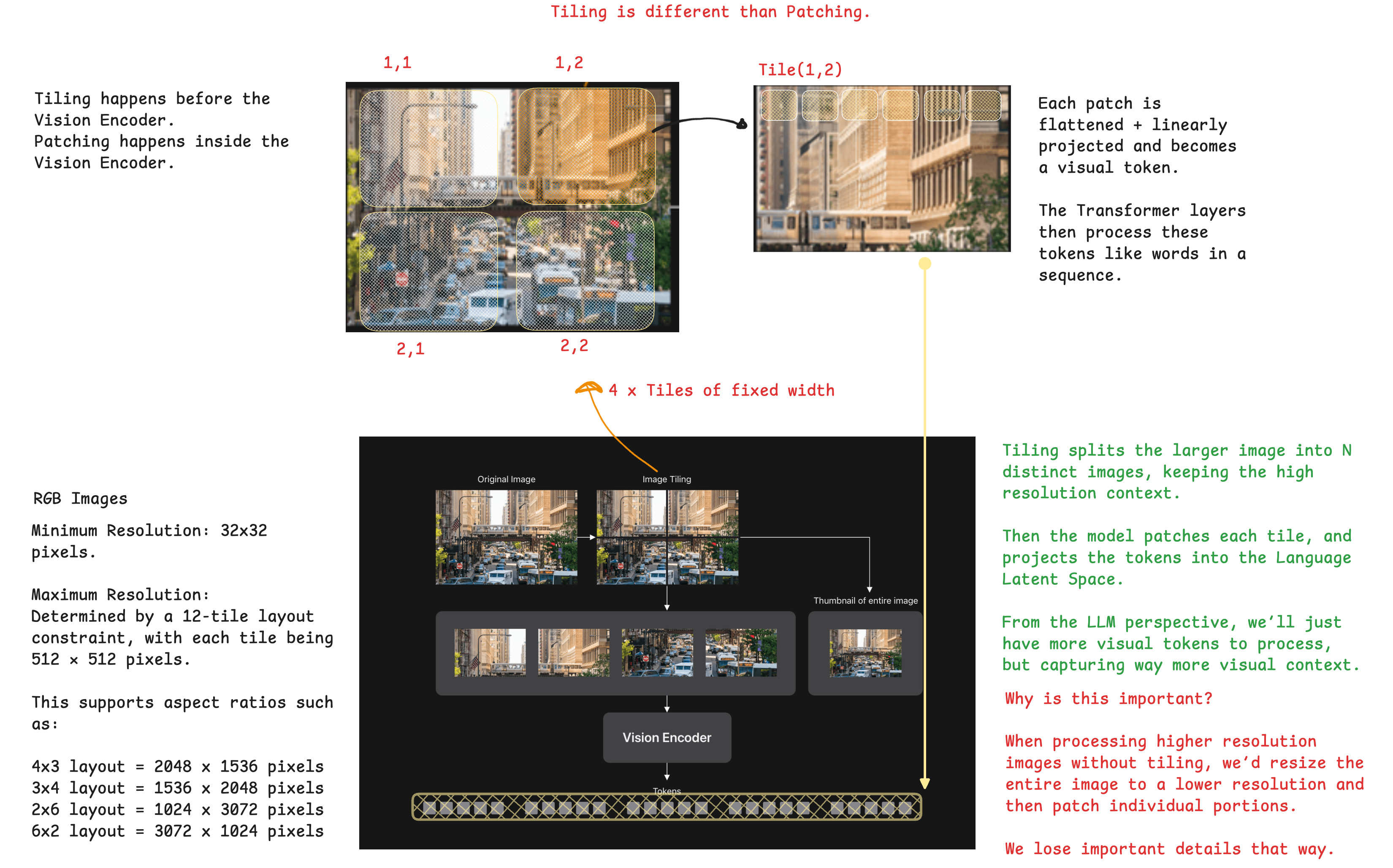
Now, in VLMs, the concept of patching is different than tiling. There’s a hierarchy order that these processing steps must follow:
Tiling = splits the entire image into multiple large tiles (e.g., 512×512 or 1024×1024), often with overlap. Each tile is then patched separately by the vision encoder.
Patching = turning a 2D image into 1D tokens with positional encodings, such that the Transformer knows how patches relate to each other across an image.
Tiling and Patching are concepts used in all Foundation Models (e.g, GPT, Gemini, Claude) or VLMs. If we have high-resolution images, or ones with weird aspect ratios (i.e, very tall PDFs, panoramic images), or images with dense text and diagrams, we split them into different tiles to capture all the visual context.
Then, each tile is patched individually such that the Transformer knows how image regions relate (i.e, Patch 1 from Tile 1, with Patch 64 from Tile 2).
Note: If we were to use patching alone, we’ll generate huge numbers of patches filling-up the entire context of the LLM.
Now that we have understood the core ideas behind Tiling and Patching, let’s visualize them in the following Figure, which contains specific details on what resolutions and layouts the RADIO Encoder within Nano 2 VL 12B model supports:
For the next step, let’s visualize and build an idea on how the RADIO Vision Encoder extracts and represents Image Features.
3.1 How RADIO Encoder Extracts Features
This is a shorter section, but it’ll build an intuition on the effects of Multi-Resolution training of the Vision Encoder, and how exactly it can extract important dense features from images.
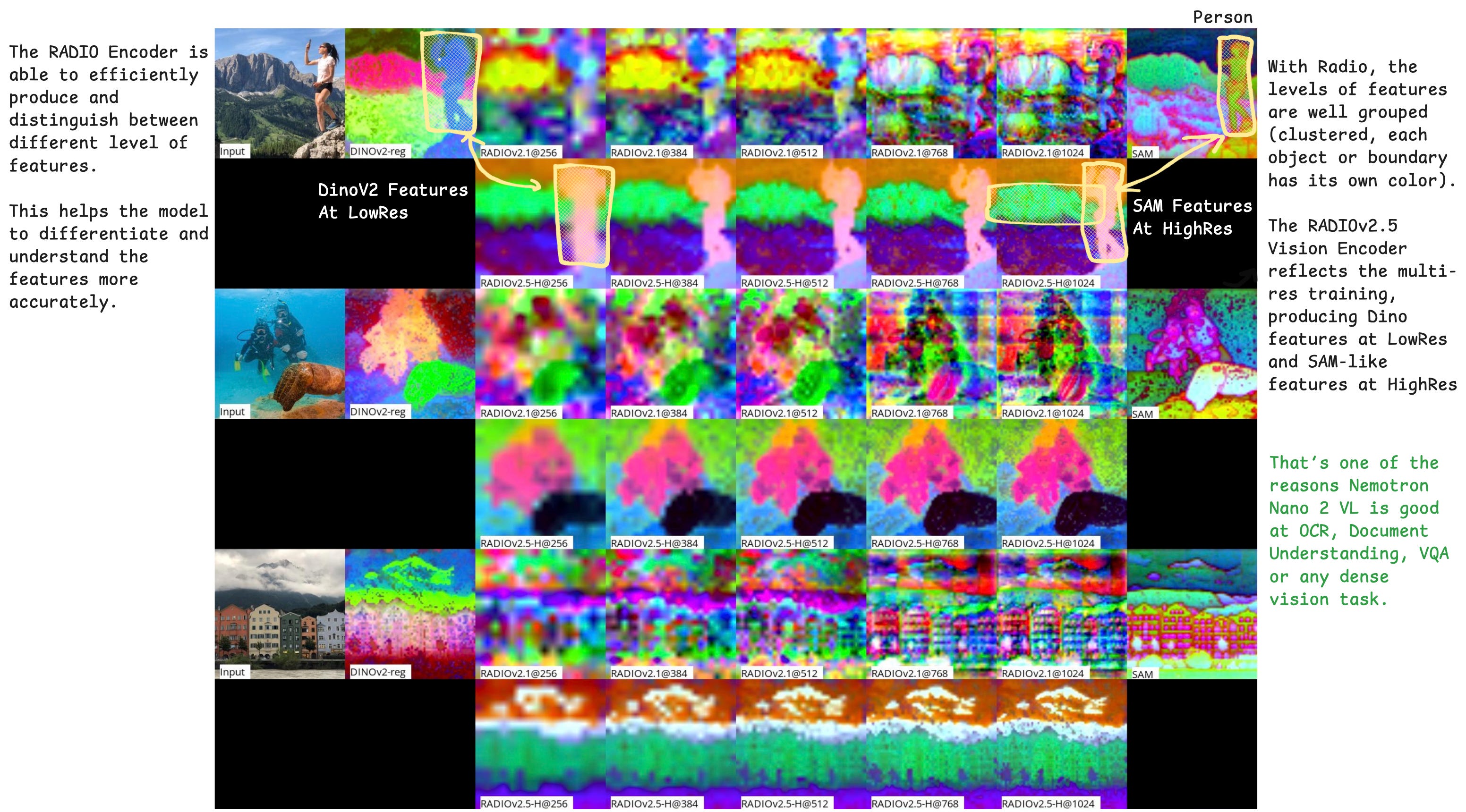
In the following Figure 13, we have a representation of the dense features mapping on different images, showcasing how RADIOv2.5 can produce low-level Meta Dino-like features and high-level Meta SAM-like features. If we look at the yellow boxes with hashed outlines, we can see the distinct clustering of features part of the same object.
In the first image, for example, there is a clear distinction between the Person (blue), Forest(green), and Mountain(red) sections, and the features (colors) are clustered to outline fine-grained details and delimitations of objects.
3.2 How Nano 2 VL Handles Long Video Input
In this section, we cover the EVS - Efficient Video Sampling plugin that the model is using to reduce repetitive/redundant tokens on multi-image inputs, using the context window more efficiently.
Note: To understand EVS in a simple sentence, think that most video content has static elements, areas that don’t change from frame to frame. We don’t need to encode all those tokens, we can encode only the “moving areas” from a video.
Nemotron Nano 2 VL uses EVS successfully for efficient video processing, which speeds up video inference by 4x, a major speed-up, with minimal accuracy loss. Let’s understand that with an actual example, we’ll use a few images from the Joe Rogan Podcast as an example.
Note: In any podcast setting, the background rarely changes, it can largely change between 2 modes only: when either of the person is speaking.
Here, the region marked in Red rarely changes. So if we select a 60-second video portion of the podcast and pass it to Nemotron Nano 2 VL, we’ll fill just a small slice of the Context Window of the model, leaving a lot of room for generation text tokens, longer video, reasoning tokens, etc.
That’s because the visual information was compressed to remove or merge areas that don’t change in the video, and that’s thanks to what EVS does.
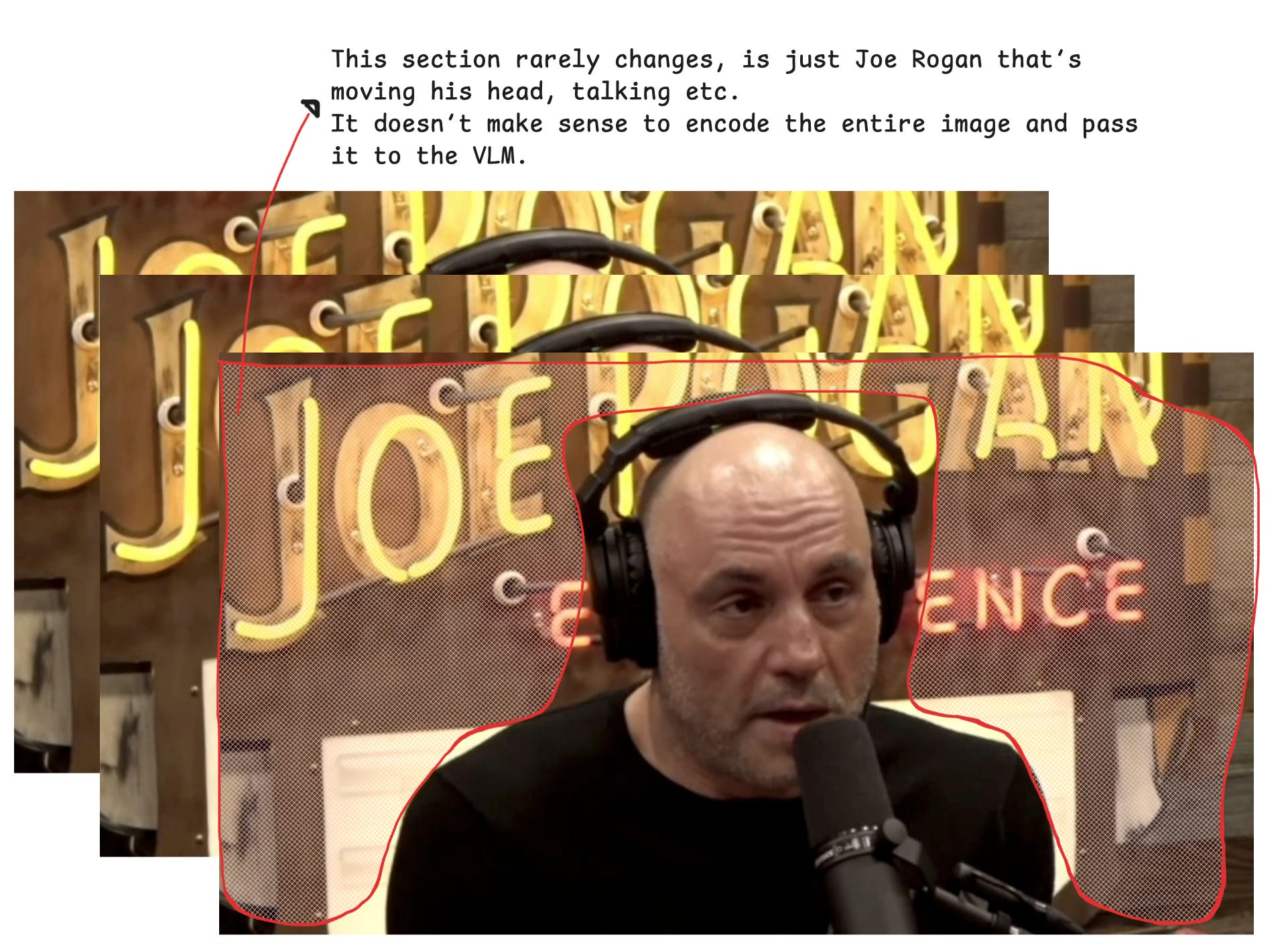
For a more robust overview of EVS and how it works, we can inspect Figure 15:

As a summary, EVS improves inference throughput, up to 4x, while maintaining the accuracy and working outside of the model, as a pre-processing step to shrink and compress Vision Tokens, before passing them to the model.
In the next section, we’ll provide a brief overview of the Datasets and Training Recipes used to train the Nemotron Nano 2 VL model.
4. The Open Source Aspect
In this section, we’ll have a look at the Training Recipe, which describes how the model was trained, aligned, on which datasets, and for how long. This is one important aspect that defines a truly Open model.
Nemotron Nano V2 VL was trained via Pretraining + 4-stage SFT pipeline. SFT stands for Supervised Finetuning, and it implies custom-engineered datasets and samples to align the model to specific behaviours.
0. Pretraining - Warming Up (36B tokens)
This stage focuses on aligning the RADIOv2.5 vision encoder with the frozen Nano 2 12B Language Model. From the architecture in Section 3, we had the Vision Projector layer, which is an MLP (Multi Layer Perceptron) responsible for projecting Vision Tokens into Language Space.
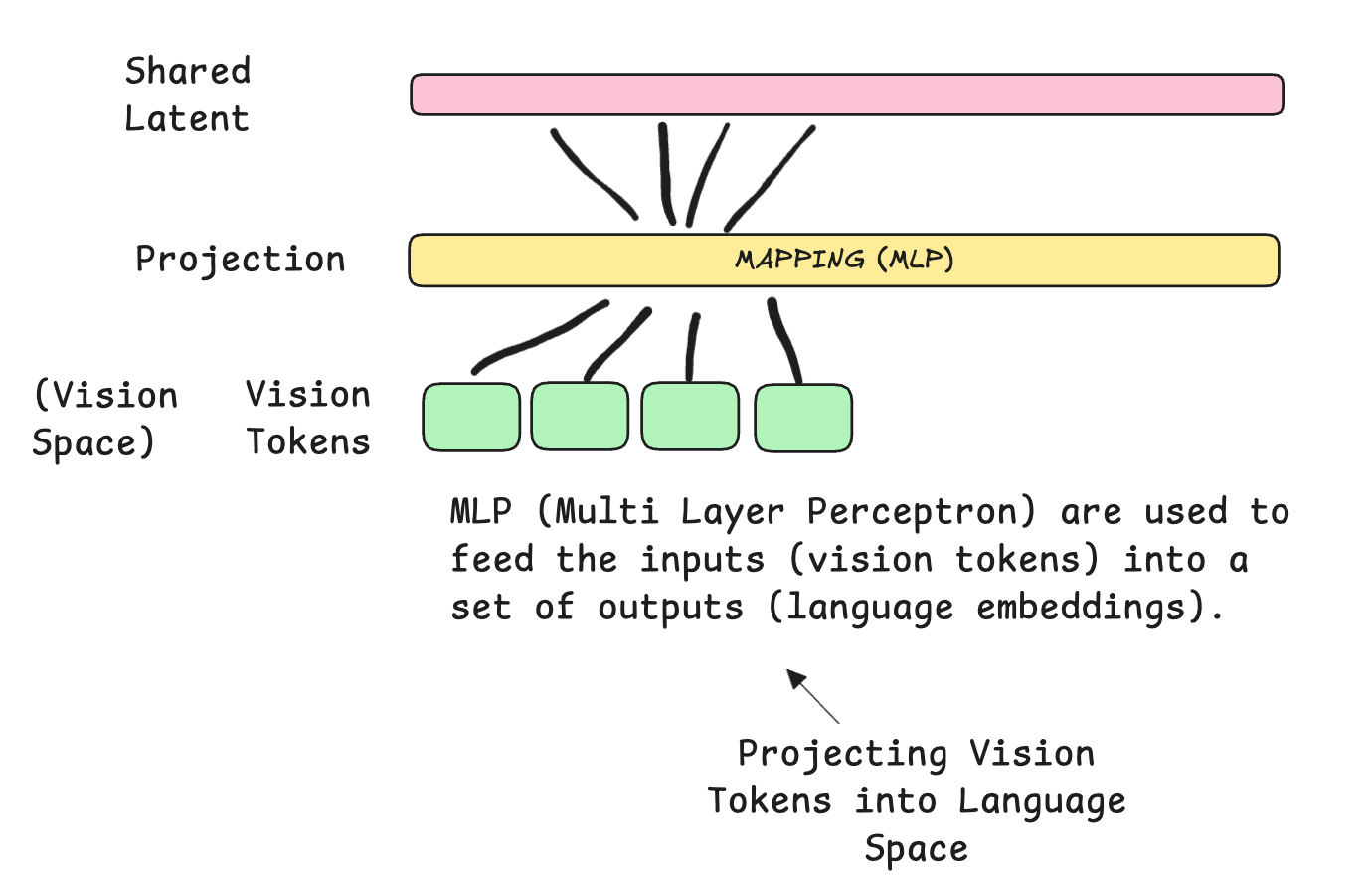
The training set included ~2.2M multimodal samples (captioning, VQA, grounding, OCR, document extraction), aiming to stabilise early multimodal alignment without affecting language capabilities (LLM was frozen in this setup).
1. Core Multimodal SFT-1 (112B Tokens, 16k Context Size)
This was the main data stage and the largest contribution to quality. Datasets cover 40B text tokens on reasoning, code, math, multilingual dialogue, and 72B multimodal tokens on captioning, TextVQA, DocVQA, ChartQA, and more.
The main outcome of this stage was strong OCR capabilities, general VQA, and document understanding and reasoning.
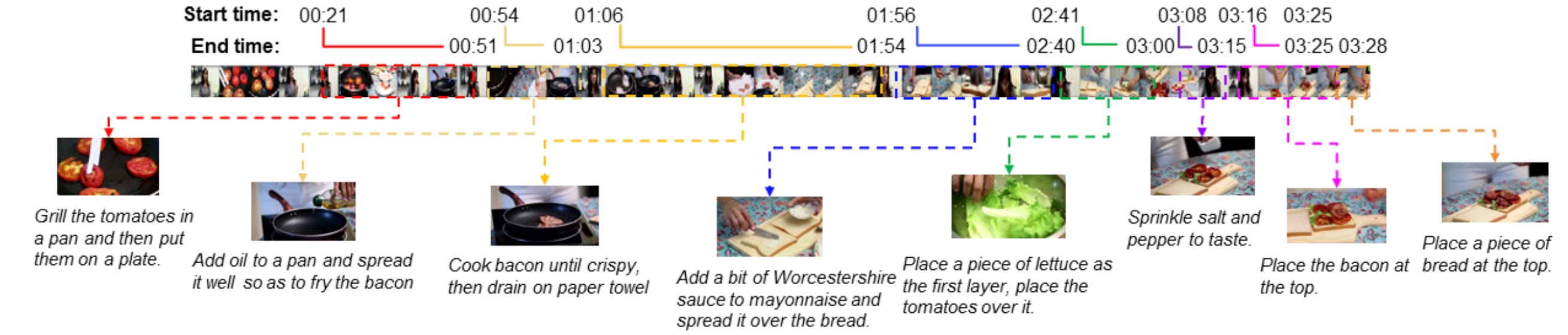
2. Video & Multi-Image SFT (55B Tokens, 49k Context Size)
This stage focused on building long-context and temporal reasoning. Datasets include Kinetics, YouCook2, ActivityNet, and VideoQA datasets, all of which contain multiple short clips of performing different actions. Below you can find an example of an entry from the YouCook2 dataset:
3. Code/Text Recovery (15B Tokens, 49k Context Size)
During the previous two stages that focused on multimodal reasoning, the team behind Nemotron Nano 2 VL noticed that code-reasoning abilities dipped, so this stage aims to recover the accuracy on the underrepresented text & code reasoning tasks.
This stage focused on code reasoning (~1M samples) to recover text abilities, restoring math, code, and text reasoning benchmarks.
4. Long-Context Scaling (12B Tokens, up to 300k Context Size)
The fourth and final stage focused on building multi-image reasoning and long-video understanding, emphasizing long context. Remember, the Nano 2 VL model has a 128k context window, allowing it to process large inputs, and this stage aligned the model to those characteristics.

Having these details helps developers trust the model they’re building on top of, be able to explain and interpret the outputs, and mitigate biases.
Note: All the details in this section, are extracted and summarized from the Research Paper, which I recommend you reading.
5. The Model on HuggingFace
You can find and get started with Nemotron Nano 2 VL models on NVIDIA’s HuggingFace Collection. The Nano 2 VL model comes in 3 different quantizations, BF16, FP8, and NVFP4 (i.e, NVIDIA’s new FP4 format compatible with Blackwell Architectures).

The models are zero-day compatible with vLLM, so you could follow the tutorial on the model card from HuggingFace, starting a vLLM server and building the client to interact with it. Additionally, you can test the model on Open Router or Baseten and Hyperbolic, as well as deploy it pre-packaged using NVIDIA NIM (NVIDIA Inference Microservice).
6. Video Demo
7. Conclusion
In this article, we’ve covered the Nemotron Nano 2 VL, an open-source, small Agentic AI-ready model, specifically tuned for multi-image reasoning, document understanding, and video understanding.
We’ve started by comparing it with the previous version, the Llama-3.1-Nemotron-VL, across the benchmark results and architecture components, outlining how the newer model brings improvements at each level, from accuracy to inference throughput.
The Nano 2 VL model is the leading open SVLM (Small Vision Language Model) on a complex OCR benchmark (the OCRBenchV2), mainly thanks to the Training Recipe and Architecture improvements it brings.
We’ve also unpacked the Vision Encoder (RADIO v2.5-H), Text Decoder (Nano 2 12B), and the EVS Plugin for long-video inputs, as well as iterating and explaining the finetuning stages and dataset used to train this model, and showcased a short demo on how the model does using a set of 6 pages from a PDF document.
Thank you for reading! See you next week
References
[1] NVIDIA. (2025). Nemotron Nano V2 VL: Model report. arXiv. https://arxiv.org/abs/2511.03929
[2] NVIDIA. (2025). Llama-3.1-Nemotron-Nano-VL-8B-V1. Hugging Face. https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-VL-8B-V1
[3] Bagrov, N., Khvedchenia, E., Tymchenko, B., Geifman, Y., Zilberstein, R., & the NVIDIA team. (2025). Efficient Video Sampling (EVS): Pruning temporally redundant tokens for faster VLM inference. arXiv. https://arxiv.org/abs/2510.14624
[4] Heinrich, G., Ranzinger, M., Yin, H., Molchanov, P., & Pan, Y. (2025). RADIOv2.5: Improved baselines for agglomerative vision foundation models. arXiv. https://arxiv.org/pdf/2412.07679
[5] Wang, H., Maaz, M., Khan, S., & colleagues. (2025). LongVideoBench: A benchmark for long-context video understanding in large vision-language models. arXiv. https://arxiv.org/abs/2407.15754
[6] Wang, H., & Team. (2025). MMBench-Doc: Benchmarking long-context document understanding with visualizations. arXiv. https://arxiv.org/abs/2407.01523
[7] ling99. (n.d.). OCRBench-v2 leaderboard. Hugging Face Spaces. https://huggingface.co/spaces/ling99/OCRBench-v2-leaderboard
[8] LMMS-Lab. (n.d.). AI2D dataset. Hugging Face Datasets. https://huggingface.co/datasets/lmms-lab/ai2d
Regarding the topic of the article, thank you for this insightful breakdown. Emphasizing smaller, efficient VLMs like the Nano 2 VL 12B is crucial. This shift toward accessible, high-performing agentic AI will profoundly impact real world applications. Your analysis is very clear.